
Anthropic released Claude Opus 4.8 on 28 May 2026 (Anthropic announcement). For marketing teams the most useful change is not a higher benchmark score. It is that the model is roughly four times less likely than Opus 4.7 to let a flaw in its own work pass without flagging it, a result Anthropic reports in its launch post and system card. In plain terms, that means fewer confident-but-wrong claims in your copy and less time spent fact-checking AI drafts before they reach a client. Standard pricing is unchanged, and a cheaper fast mode makes customer-facing tools more affordable to run. Here is what Claude Opus 4.8 for marketing teams actually means in practice.
We have spent the day since launch putting it through the work we actually do: drafting, research synthesis, content audits and the kind of long-document reading that eats hours. What follows is stripped of the launch-day noise.

Claude Opus 4.8 Overview
| Claude Opus 4.8 | Details |
|---|---|
| Released | 28 May 2026, 41 days after Opus 4.7 |
| API model name | claude-opus-4-8 |
| Standard pricing | $5 / $25 per million tokens (input / output), unchanged from Opus 4.7 |
| Fast mode | $10 / $50 per million tokens, about 2.5x speed, three times cheaper than previous fast mode |
| Headline change for marketers | More reliable; around 4x less likely to leave its own errors unflagged |
| Where you will meet it | claude.ai, Claude apps, Pro/Max/Team/Enterprise plans, the Claude API, AWS Bedrock, Google Vertex AI, Microsoft Foundry, GitHub Copilot |
| Primary source | Anthropic, Introducing Claude Opus 4.8 |
What Is Claude Opus 4.8, and Why Should a Marketing Team Care?
Claude Opus 4.8 is Anthropic’s most capable public model, and it replaces Opus 4.7 as the default Opus everywhere Claude runs. Developers reach it through the Claude API as claude-opus-4-8. It is available on the paid Claude plans (Pro, Max, Team and Enterprise), and across Amazon Bedrock, Google Cloud Vertex AI and Microsoft Foundry. It also landed in GitHub Copilot on launch day, though Copilot users should note it arrived with a 15-times premium request multiplier until usage-based billing begins on 1 June 2026. You will also meet it inside writing, research and analytics tools your team or your clients already use that are built on the Claude API. When the model underneath those tools gets steadier, the output you ship gets steadier too, often without anyone changing a setting.
That is the real reason to pay attention. Most marketers will never touch the API directly. They feel a model upgrade through the products it powers: the content assistant in their CMS, the research tool the strategy team relies on, or the chatbot on a client’s site. Opus 4.8 is the engine behind a growing share of that work.
The timing matters for anyone planning a process around AI. Opus 4.7 landed on 16 April 2026. Opus 4.8 followed just 41 days later, the shortest gap between Opus releases so far. TechCrunch flagged the speed as unusual for Anthropic and linked it to the muted reception Opus 4.7 had received. Models are moving quickly. Any workflow you design should expect the next version within weeks, not years, which is an argument for a light, repeatable way of adopting updates rather than hard-wiring your process to one model.

How Does Claude Opus 4.8 Compare to Opus 4.7?

On the headline tests Anthropic published, Opus 4.8 beats Opus 4.7 across the board, with the clearest gain in agentic coding. The jumps are real but mostly incremental, which fits Anthropic’s own framing of the release as an iteration rather than a leap.
| Benchmark (what it measures) | Opus 4.7 | Opus 4.8 |
|---|---|---|
| Agentic coding (SWE-bench Pro) | 64.3% | 69.2% |
| Coding (SWE-bench Verified) | 87.6% | 88.6% |
| Reasoning with tools (Humanity’s Last Exam) | 54.7% | 57.9% |
| Agentic computer use (OSWorld-Verified) | 82.8% | 83.4% |
These figures are self-reported by Anthropic in its launch announcement and system card. A few of the tests it tracks changed version between Opus 4.7 and Opus 4.8, so not every number is a clean like-for-like comparison, and independent results will take time to appear. For a marketing team the takeaway is simpler than the table: the model is a little sharper at most things and noticeably steadier on long, multi-step work, which is where you were already relying on it.
How Does It Compare to GPT-5.5 and Gemini 3.1 Pro?
Against the other frontier models, Opus 4.8 comes out ahead on most of the agentic tests Anthropic ran, though not all of them. On SWE-bench Pro it sits more than ten points clear of both GPT-5.5 and Gemini 3.1 Pro. The margin narrows on computer use but still favours Opus, and on Anthropic’s knowledge-work measure, GDPval-AA, it scores 1890 against GPT-5.5’s 1769. The honest exception is terminal coding: on Terminal-Bench 2.1, GPT-5.5 edges ahead, so a team whose work is mainly a single agent in a shell has a closer call to make than the rest of the table suggests.
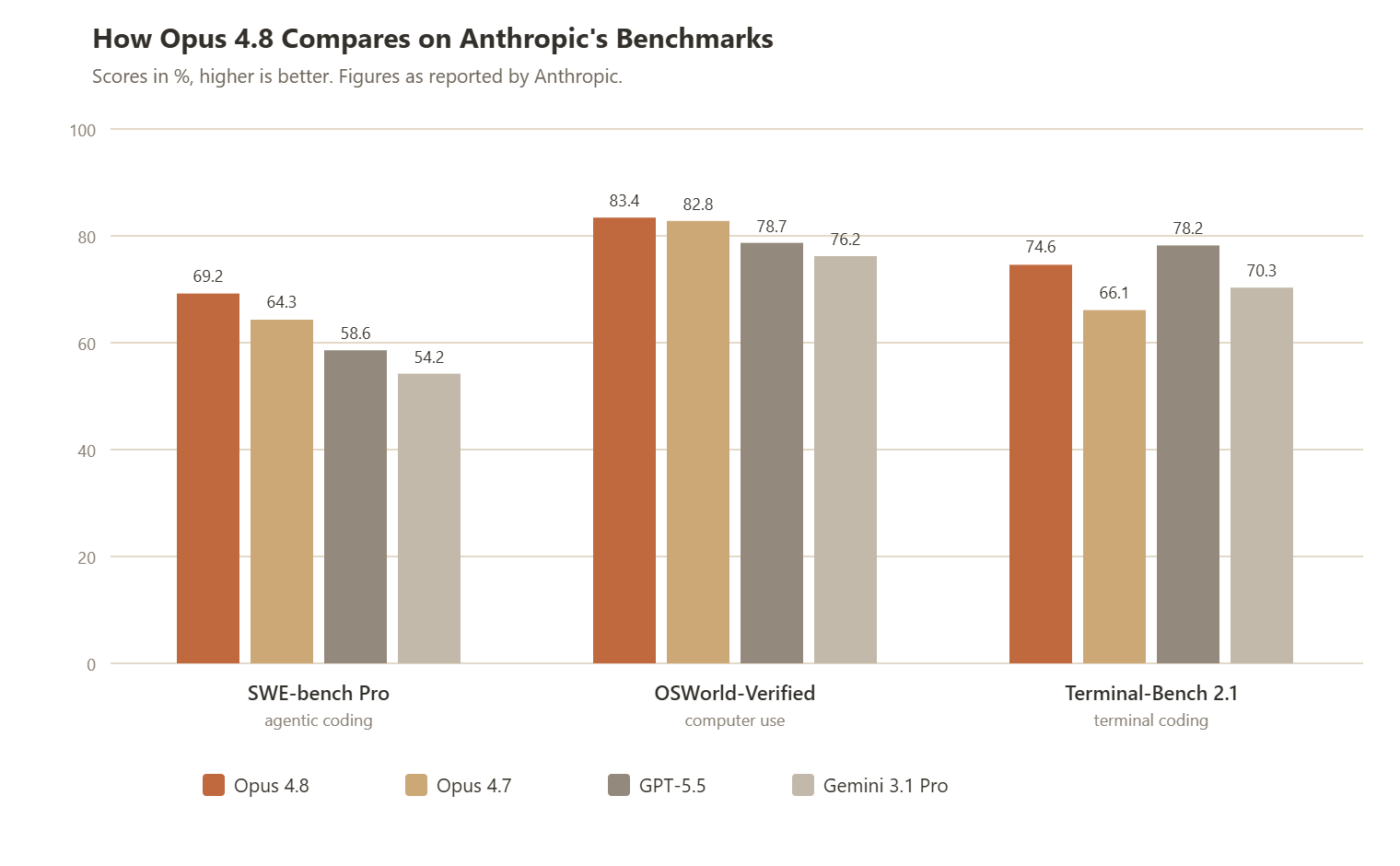
Figures are as reported by Anthropic in the Opus 4.8 system card. On Terminal-Bench 2.1, GPT-5.5’s 78.2% is measured on the shared Terminus-2 harness; Anthropic notes it reaches 83.4% on its own Codex CLI harness, which is why you may see a higher number for GPT-5.5 quoted elsewhere.
What Does “a More Honest Model” Mean for Your Content?
This is the part of the release marketers should read twice. Anthropic’s central claim for Opus 4.8 is honesty, by which it means the model’s stated confidence now tracks its actual work more closely. Its evaluations found the model around four times less likely than Opus 4.7 to let flaws in its own output pass unremarked, and less likely to assert something it cannot support, as set out in the launch announcement.
The expensive failure mode of AI copy is the confident false statement. A product specification that is subtly wrong. A statistic with no source behind it. A superlative the client cannot actually stand behind. In the UK that is not merely embarrassing, it is a compliance risk. The Advertising Standards Authority requires marketers to hold evidence for objective claims under CAP Code rule 3.7 on substantiation, and “the AI wrote it” is no defence if a misleading line ends up in a paid campaign. A model that hedges where it should, and raises a hand over a claim it cannot back, lowers the odds that a fabricated sentence reaches a published landing page.
None of this lets you stop checking. A human still has to verify the facts, and reading the improvement as a reason to skip that step would be a costly mistake. What it changes is the volume. Fewer errors slip through, so your sign-off catches fewer needles in a smaller haystack. Keep the review step. Just expect it to be lighter.
A word on the word itself. A language model has no intention to be truthful about, so “honest” is a generous label for what is really better calibration. The behaviour is what counts, and the behaviour, a model that overstates its progress less often, is exactly the thing a marketing team wants improved. Anthropic’s alignment team also reports that rates of misaligned behaviour such as deception now sit well below Opus 4.7 and close to its best-aligned model, a comparison VentureBeat covered in detail.
Where Claude Opus 4.8 for Marketing Teams Pays Off
The gains concentrate in tasks where the model works for a stretch and you review the result, rather than quick back-and-forth chat. Research synthesis, first drafts at volume, repurposing one asset into many formats, and reading long documents to pull out what matters are where you will feel the difference.
Tasks Worth Handing Over
A few examples from the kind of work this suits:
- Feed it a 90-minute customer interview and you get back a messaging hierarchy and a few campaign angles, with the thin quotes flagged instead of quietly dressed up.
- A quarter’s social calendar can come straight from the brand guidelines, roughed out for a writer to sharpen rather than build from scratch.
- During a site re-platform it can hold one tone of voice across a 300-page product library, which is usually the part that slips.
- Reading a stack of competitor brochures and PDFs and extracting their claims into one comparison your strategists can argue with.
Where to Keep a Human in Charge
What it will not do is replace the parts of agency work that earn the fee. It does not own the strategy, it does not hold the client relationship, and it has no taste of its own. Think of it as a quick, capable junior who needs a brief and a check, now slightly more willing to admit when it is unsure. The agencies that get value from it are the ones who put it on the right tasks, not the most tasks.
Do You Even Need Opus 4.8, or Would a Cheaper Model Do?
Often a cheaper model will do, and that is the question to ask before you default to Opus for everything. Opus is Anthropic’s premium tier, priced for the hard problems: long-context reasoning, multi-step work, and tasks where a wrong answer is costly. For high-volume, low-stakes drafting, a faster and cheaper model in the Claude line, such as Sonnet, may give you most of the quality at a fraction of the bill.
The sensible pattern is to route by stakes. Reserve Opus 4.8 for the work that justifies the premium, a client-facing strategy document or a regulated claim, and send the routine, repetitive jobs to a lighter model. Check the current Sonnet and Haiku pricing and capabilities before you decide, because the tiers move, and the right split for your team is the one your own cost and quality figures support, not a rule of thumb from a blog.
What Is Effort Control, and How Does It Affect Your AI Budget?
Effort control is the new dial next to the model selector on claude.ai and in Cowork, on every plan. It governs how hard Claude works on a given reply. Turn it up and the model thinks more, for a better answer that costs more and arrives slower. Turn it down and it replies faster while drawing on your rate limits more gently. Anthropic describes the control and its default in the launch announcement.
For an agency managing AI spend across several client accounts, this is a genuinely useful lever. You can match effort to the stakes. A throwaway internal summary does not need the heaviest setting. A client-facing strategy document does. Opus 4.8 defaults to high effort, which Anthropic judges to be the best balance for most work, and on coding-style tasks that default spends a similar number of tokens to Opus 4.7’s while returning better results. So your baseline does not quietly cost more after the upgrade.
The practical rule we use: leave it on high for everyday work, step up to “extra” (labelled xhigh in Claude Code) for hard or long-running jobs, and reserve “max” for the rare task that justifies the spend. Whatever you choose, measure tokens per task on your own traffic. Aggregate figures from a launch post will not match how your team actually prompts.
Dynamic Workflows and a Cheaper Fast Mode
Two companion launches arrived with the model, and they pull in different directions: one lets Claude take on much bigger jobs, the other makes quick, interactive use far cheaper.
Dynamic Workflows in Claude Code
Dynamic workflows, a Claude Code feature in research preview, lets the model plan a large task, run hundreds of subagents in parallel within one session, and verify its output before reporting back. Anthropic says it can carry out codebase-scale migrations across hundreds of thousands of lines of code, from kickoff to merge, with the existing test suite as the bar (see Anthropic’s dynamic workflows post). A smaller change in the same release lets developers update Claude’s instructions mid-task through the Messages API, which matters if your team builds agents that adjust permissions or context as they run.
What This Means if You’re Not on a Dev Team
For most marketing teams this is indirect. Dynamic workflows lives in Claude Code, the developer tool, so you are most likely to benefit through a product partner or a technical build rather than by using it yourself. If your agency handles site re-platforms, large template migrations or anything that touches a real codebase, it is worth a look. If you do not, treat it as context rather than a tool you will reach for.
Fast Mode: Frontier Quality at Interactive Speed
Fast mode runs the same Opus 4.8 model at about 2.5 times the speed, and Anthropic has made it three times cheaper than fast mode on previous Claude models, at $10 per million input tokens and $50 per million output tokens. That matters for anything customer-facing that cannot keep a user waiting: an on-site assistant, a chat-based product finder, an interactive campaign tool. Frontier-grade responses at interactive speed used to be too expensive to justify for many of these. They are now closer to affordable.
How Much Does Claude Opus 4.8 Cost?
Standard and Fast Mode Pricing
Standard pricing is unchanged from Opus 4.7, according to Anthropic’s availability section. You pay $5 per million input tokens and $25 per million output tokens. Fast mode costs double that for roughly 2.5 times the speed.
| Mode | Input (per million tokens) | Output (per million tokens) |
|---|---|---|
| Standard | $5 | $25 |
| Fast mode | $10 | $50 |
Discounts and Currency to Check
Cached reads and batch processing carry their usual discounts, but the exact rates are easy to misquote, so check the current Claude API pricing page before you build a client budget on them. Anthropic quotes prices in US dollars, so convert at the rate that applies to your billing and remember that token usage, not the headline rate, is what actually drives your bill.
Should Your Team Switch From Opus 4.7?
Yes, if your work leans on research, long-document analysis or high-volume drafting, because the honesty improvement pays off most exactly where you review the output less closely. For quick conversational use, the day-to-day difference will be modest, and you would be forgiven for not noticing it. Anthropic itself calls the release a modest but tangible improvement, which is an unusually candid thing for a launch post to say and, on our testing, a fair one.
So do not rebuild your stack around it. The sensible path is the one you would take for any model change: move your prompt tests and a sample of real client tasks onto the new version, confirm the behaviour holds, then switch. Because the API model name is claude-opus-4-8, any integration pinned to the previous version keeps running on 4.7 until you choose to update it. Migrate on evidence, not on launch-day excitement.
Keeping AI Content Brand-Safe: A Short Governance Note
A more reliable model lowers your error rate, but it does not change who is accountable for what you publish. Draw the governance line before you scale, not after something has gone wrong. On client-facing work that means a named person signs off every piece. Claims that need proof get their source logged as they are made, and you hold a record of what the model wrote and who signed it off. Decide in advance which tasks the model may complete on its own and which always need review, and write it down. This is the part that protects the brand, and it is also the part a client will ask about. Treat Opus 4.8 as a capable assistant operating inside that frame, not as a replacement for it.
What This Release Signals for AI in Marketing
Opus 4.8 is the best public model Anthropic has, but it is not the most capable model the company holds. That is Claude Mythos Preview, a higher-intelligence model kept back from general release while Anthropic builds stronger cyber safeguards around it, currently used by a small set of organisations under Project Glasswing. Anthropic says it expects to bring Mythos-class models to all customers in the coming weeks. Read that timeline with some scepticism, and assume the broadly released version may be more constrained than the preview.
The business backdrop says something too. Anthropic announced a $65 billion Series H round on the same day, putting its valuation at $965 billion (Anthropic, Series H), ahead of OpenAI’s reported $852 billion. Heavy investment, a release every six weeks, and a clear push to put Opus in front of more paying users.
For a marketing team, the strategic read is straightforward. Capability is rising and cost is, in places, falling, both in your favour. The right response is not to chase every release or to bet your process on a single model. It is to build a light, documented way of testing and adopting new versions, and a clear governance line on what AI may and may not do in client-facing work. Governance is the part that will protect the brand. The model will keep changing.